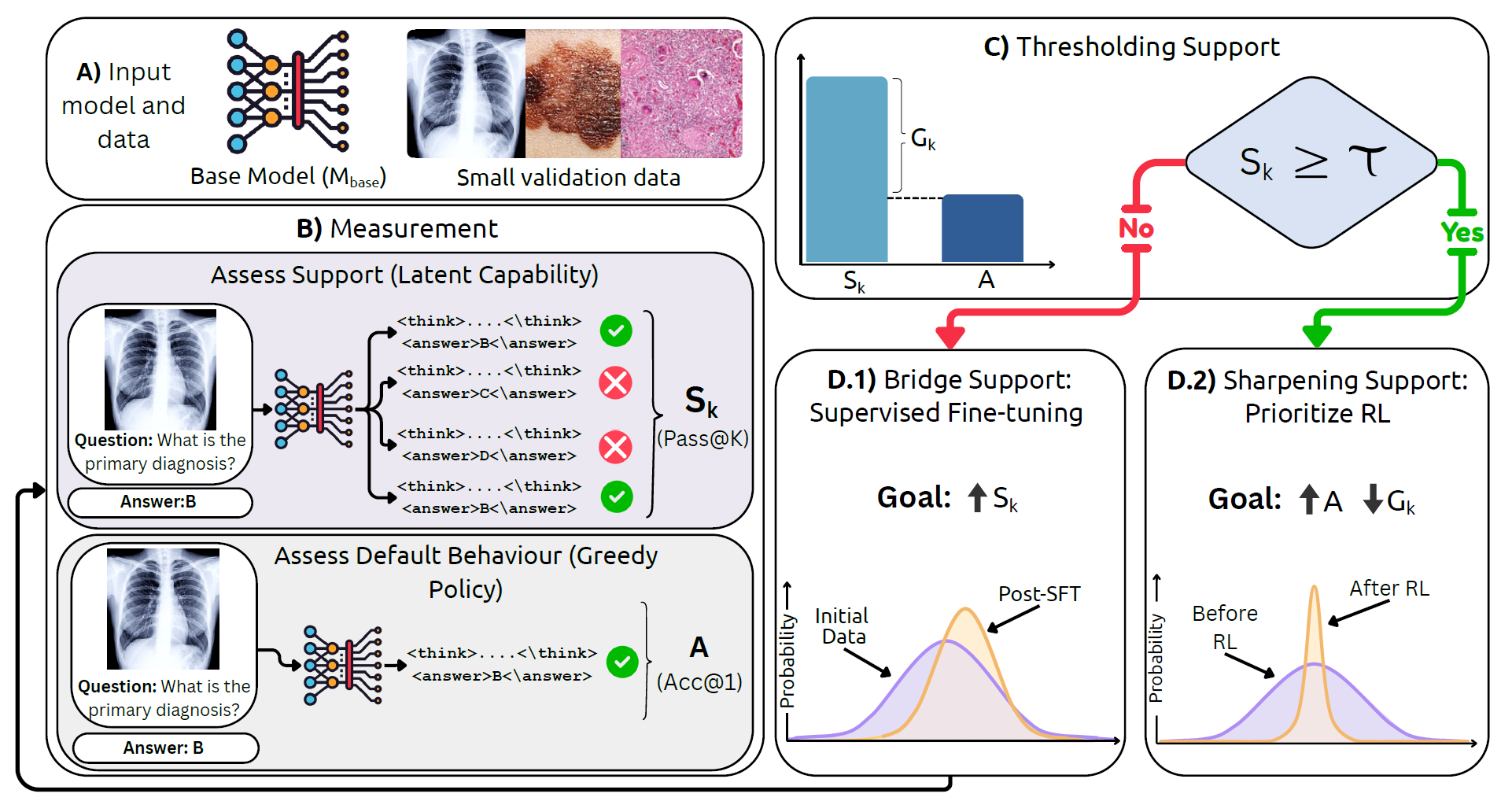
Overview
Reinforcement learning (RL) is increasingly used to post-train medical vision-language models (VLMs), but it is still unclear when RL helps and whether it improves medical reasoning or mostly sharpens behaviors already present in the base model. In practice, some RL checkpoints improve accuracy on a subset of benchmarks, while others fail to transfer across modalities or even reduce the model’s latent capability.
We introduce MedBridgRL, a boundary-aware framework that studies and operationalizes this question through the lens of Pass@K. MedBridgRL measures a model’s support (latent capability) using Pass@K, compares it to greedy accuracy (Acc@1), and uses their gap to diagnose whether the model is limited by weak support or by poor sampling efficiency.
The resulting recipe is simple: (1) if support is low, bridge the distribution with targeted medical data (SFT or task/modality-proximal training) to raise Pass@K; then (2) once support is sufficient, apply GRPO-style RL to sharpen the distribution and improve Acc@1 and sampling efficiency. We validate this recipe by RL post-training an OctoMed-initialized model on a small, balanced PMC-style MCQ set and evaluating across multiple medical VQA benchmarks.
BibTeX
@misc{jeddi2026doesrlhelpmedical,
title={When Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains},
author={Ahmadreza Jeddi and Kimia Shaban and Negin Baghbanzadeh and Natasha Sharan and Abhishek Moturu and Elham Dolatabadi and Babak Taati},
year={2026},
eprint={2603.01301},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.01301},
}